
Qwen3-TTS: Redefining Open-Source Voice Cloning and Speech Generation
Date: January 27, 2026
Category: AI Research / Audio Synthesis
The landscape of generative audio has just witnessed a significant leap forward. The Qwen Team has officially open-sourced the Qwen3-TTS family, a suite of powerful models capable of ultra-realistic speech synthesis, instant voice cloning, and granular voice design.
Moving beyond traditional text-to-speech (TTS) limitations, Qwen3-TTS introduces a unified architecture that merges high-fidelity audio generation with the semantic understanding of Large Language Models (LLMs). Whether for real-time conversational AI or cinematic content creation, this release sets a new standard for what is possible in open-source audio.
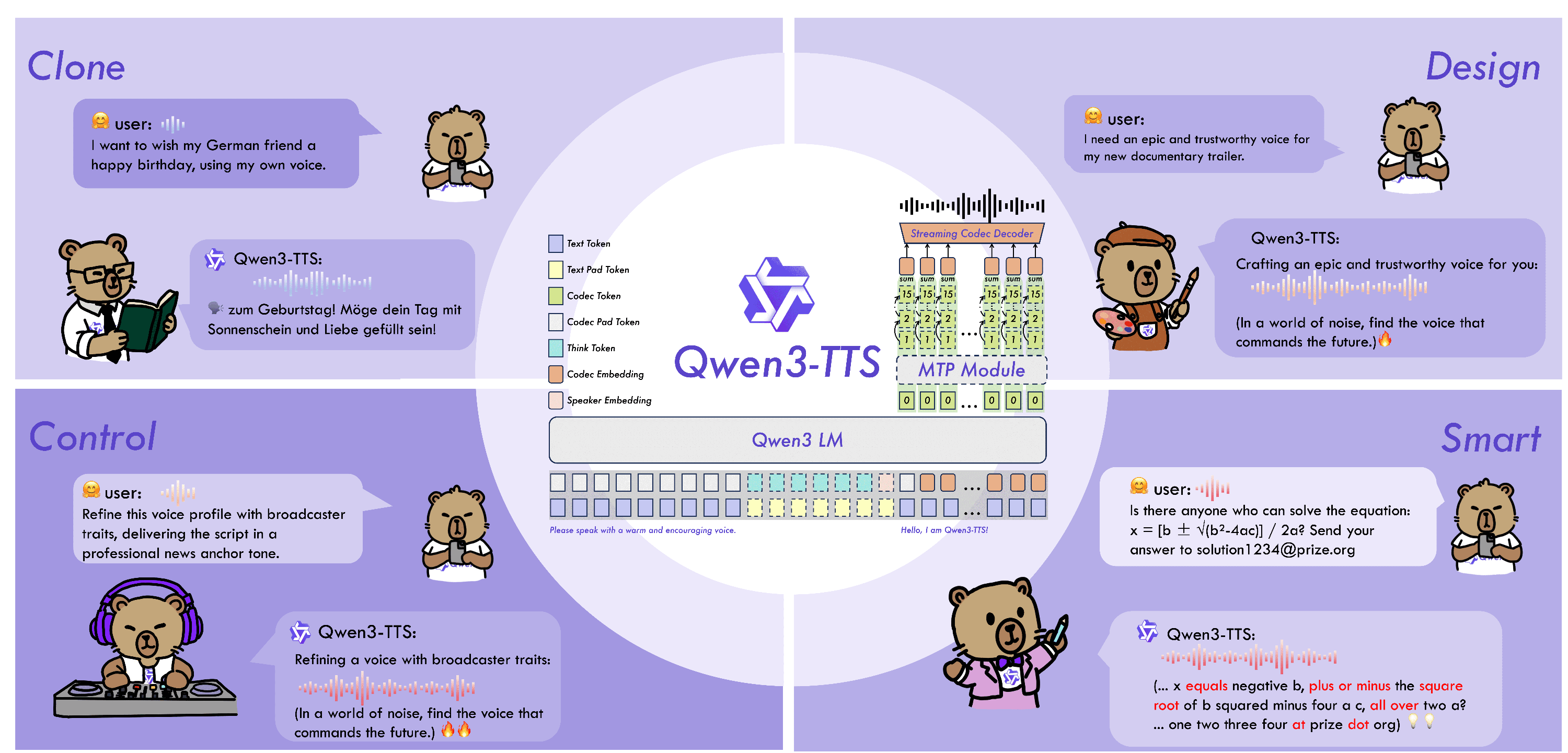
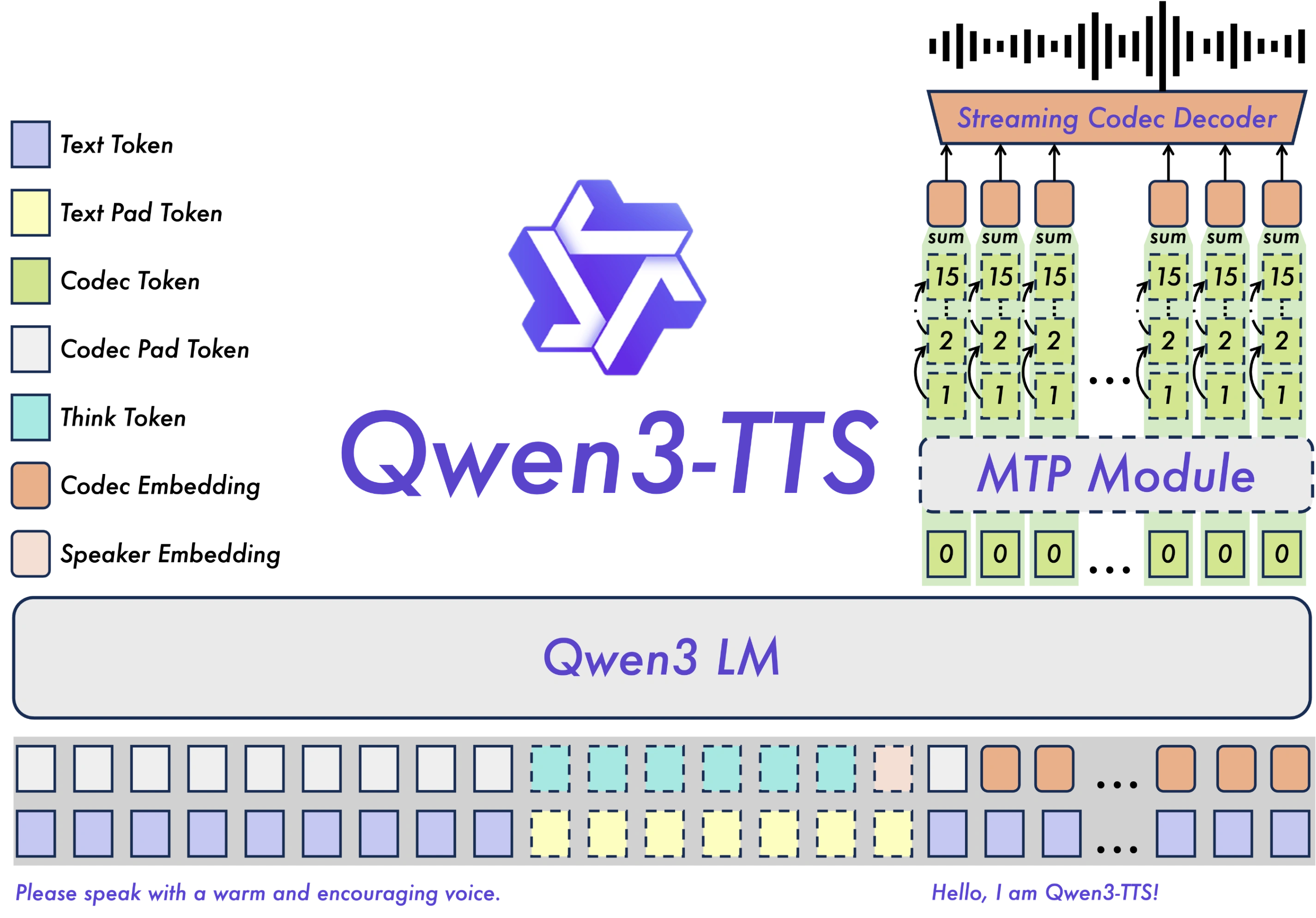
The Core Innovation: A Universal End-to-End Architecture
Unlike many contemporary models that rely on Diffusion Transformers (DiT), Qwen3-TTS adopts a lightweight non-DiT architecture. This strategic shift addresses the common bottlenecks of cascading errors and slow generation speeds found in traditional pipelines.
1. The 12Hz Multi-Codebook Tokenizer
At the heart of the system lies the proprietary Qwen3-TTS-Tokenizer-12Hz. This component is a game-changer for acoustic compression. By achieving robust representation of speech signals, the tokenizer preserves critical "paralinguistic" information—the breaths, pauses, and subtle environmental features that make speech sound human rather than robotic.
2. Dual-Track Streaming
Latency is the enemy of real-time interaction. Qwen3-TTS utilizes Dual-Track modeling, a hybrid approach that allows the model to deliver the first packet of audio after processing a single character. With an end-to-end synthesis latency as low as 97ms, it is perfectly optimized for live conversational agents and interactive applications.
Model Sizes and Capabilities
The Qwen3-TTS family is released in two distinct sizes to balance performance with computational efficiency. Both support 10 mainstream languages (including English, Chinese, Japanese, German, and Spanish).
| Model Size | Variants | Key Use Cases |
|---|---|---|
| 1.7B Parameters | VoiceDesign CustomVoice Base | Peak performance. Ideal for creating new voices from text descriptions, precise style control, and high-fidelity cloning. |
| 0.6B Parameters | CustomVoice Base | Efficiency-focused. perfect for edge deployment or cost-effective scaling while maintaining high-quality timbre control. |
1.7B Model List
| Model Name | Description | Streaming | Instruction Control |
|---|---|---|---|
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | Performs voice design based on user-provided descriptions. | ✅ | ✅ |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | Provides style control over target timbres via user instructions; supports 9 premium timbres covering various combinations of gender, age, language, and dialect. | ✅ | ✅ |
| Qwen3-TTS-12Hz-1.7B-Base | Base model capable of 3-second rapid voice clone from user audio input; can be used for fine-tuning (FT) other models. | ✅ |
0.6B Model List
| Model Name | Description | Streaming | Instruction Control |
|---|---|---|---|
| Qwen3-TTS-12Hz-0.6B-CustomVoice | Supports 9 premium timbres covering various combinations of gender, age, language, and dialect. | ✅ | |
| Qwen3-TTS-12Hz-0.6B-Base | Base model capable of 3-second rapid voice clone from user audio input; can be used for fine-tuning (FT) other models. | ✅ |
All Qwen3-TTS 1.7B models and the 0.6B model support 10 languages, including Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian.
Key Features Breakdown
1. Voice Design: "What You Imagine is What You Hear"
The Qwen3-TTS-VoiceDesign model allows users to generate entirely new voice identities using natural language prompts. Instead of searching for a reference audio file, a developer can simply type:
"A sarcastic teenage girl, fast-paced, slightly nasal, sounding bored yet authoritative."
The model interprets these semantic instructions to synthesize a voice that matches the persona, creating a new frontier for NPC creation in gaming and virtual avatars.
2. Zero-Shot Voice Cloning
For scenarios requiring specific identity replication, the Base models offer rapid voice cloning. With just 3 seconds of reference audio, Qwen3-TTS can clone a speaker's timbre with SOTA (State of the Art) similarity, functioning seamlessly across different languages (e.g., cloning a Chinese speaker to speak fluent French).
3. Granular Voice Control
The CustomVoice variants provide fine-grained control over prosody and emotion. Users can manipulate:
- Emotion: From "tearful grief" to "ecstatic shouting."
- Pacing: Adjusting speed dynamically within a sentence.
- Pitch & Intonation: Rising inflections for questions or authoritative drops for commands.
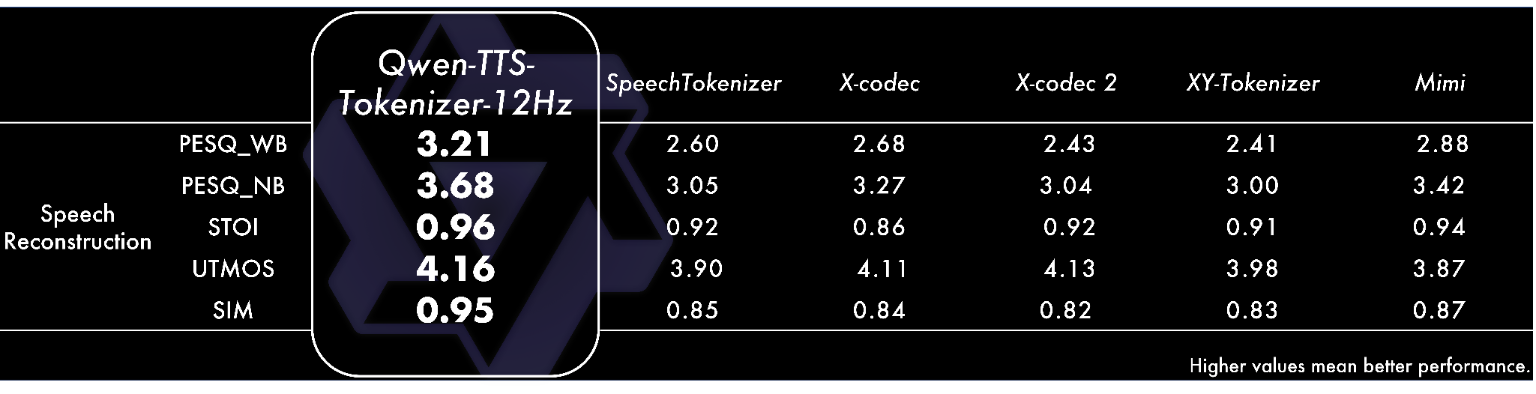
Performance vs. Competitors
Internal evaluations and standard benchmarks (such as InstructTTS-Eval and LibriSpeech) demonstrate that Qwen3-TTS outperforms several leading closed-source and open-source alternatives.
- Voice Design: Surpasses MiniMax-Voice-Design in instruction following and expressiveness.
- Cloning Stability: Outperforms SeedTTS and ElevenLabs in multilingual stability and speaker similarity (0.789 similarity score).
- Audio Quality: The tokenizer achieves a PESQ score of 3.68 (narrowband) and 4.16 on UTMOS, indicating near-lossless reconstruction of speaker information.


Practical Applications
The open-sourcing of Qwen3-TTS opens up vast possibilities for developers:
- Intelligent Customer Service: With <100ms latency, bots can interrupt and respond naturally without the awkward "processing silence."
- Global Content Localization: Dubbing videos into 10 languages while retaining the original speaker's vocal identity.
- Accessibility: Creating highly expressive, personalized screen readers for the visually impaired.
- Entertainment: Generating multi-character audio dramas or dynamic video game dialogue on the fly using the Timbre Reuse feature.
Conclusion
Qwen3-TTS represents a significant maturity in the open-source audio domain. By combining a discrete multi-codebook LM with a non-DiT architecture, Qwen has solved the "Impossible Triangle" of speed, quality, and controllability.
The models are now available on GitHub and Hugging Face, ready for fine-tuning and commercial integration.
Disclaimer: This article provides a technical overview based on the official Qwen3-TTS release notes. Performance metrics are based on the data provided at the time of launch.